|
Research
Currently, my main interests include generative models, diffusion models, personalization of generative models, simulation and beneficial adversarial attacks.
|

|
ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
David Junhao Zhang, Roni Paiss, Shiran Zada, Nikhil Karnad, David E. Jacobs, Yael Pritch, Inbar Mosseri, Mike Zheng Shou, Neal Wadhwa, Nataniel Ruiz
arXiv preprint arXiv:2411.05003, 2024
website
|

|
RealFill: Reference-driven Generation for Authentic Image Completion
Luming Tang, Nataniel Ruiz, Qinghao Chu, Yuanzhen Li, Aleksander Holynski, David E. Jacobs, Bharath Hariharan, Yael Pritch, Neal Wadhwa, Kfir Aberman, Michael Rubinstein
SIGGRAPH (Journal Track), 2024
website |
two minute papers |
data |
tweet |
code
|

|
StyleDrop: Text-to-Image Generation in Any Style
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, Yuan Hao, Irfan Essa, Michael Rubinstein, Dilip Krishnan
Conference on Neural Information Processing Systems (NeurIPS), 2023
website |
tweet |
google cloud launch |
unofficial code
|

|
DreamBooth3D: Subject-driven Text-to-3D Generation
Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, Yuanzhen Li, Varun Jampani
International Conference on Computer Vision (ICCV), 2023
website |
demo video |
tweet
|

|
Simulating to Learn: Using Adaptive Simulation to Train, Test and Understand Neural Networks
Nataniel Ruiz
Boston University, 2023 (PhD Thesis)
This thesis presents new insights into the use of adaptive simulation to train and test machine learning models, addressing the key obstacle of collecting annotated and high-quality real-world data. It presents five novel methods for adapting simulated data distributions to improve the training and testing of neural networks.
|
|
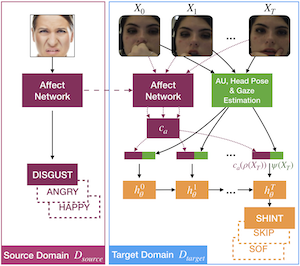
Leveraging Affect Transfer Learning for Behavior Prediction in an Intelligent Tutoring System
Nataniel Ruiz, Hao Yu, Danielle A. Allessio, Mona Jalal, Thomas Murray, John J. Magee, Jacob R. Whitehill, Vitaly Ablavsky, Ivon Arroyo, Beverly P. Woolf, Stan Sclaroff, Margrit Betke
IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2021
IEEE Transactions on Biometrics, Identity and Behavior (T-BIOM), 2022
journal paper
(Oral and Best Poster Award - 4% award rate)
|

|
Learning To Simulate
Nataniel Ruiz, Samuel Schulter, Manmohan Chandraker
International Conference on Learning Representations (ICLR), 2019
poster
|

|
Detecting Gaze Towards Eyes in Natural Social Interactions and Its Use in Child Assessment
Eunji Chong, Katha Chanda, Zhefan Ye, Audrey Southerland, Nataniel Ruiz, Rebecca M. Jones, Agata Rozga, James M. Rehg
UbiComp and Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT), 2017
(Oral Presentation and Distinguished Paper Award - 3% award rate)
bibtex
|
|